Conventional databases are engineered to minimize data transport and query latency by distributing computational tasks across local nodes. This storage-compute connected design becomes problematic as data quantities and needs for real-time analysis increase. In a business environment where "cost" and "efficiency" are crucial, problems like inefficient compute resources, complicated data distribution and deployment, and expensive maintenance shoot up your observability bills, which is intolerable. It is imperative to have a decoupled architecture between storage and compute that can scale computation independently.
This blog describes how a storage-compute separation helps reduce costs and increase efficiency.
Why is storage-compute coupling a problem?
Imagine a company generating 1 terabyte of incremental log data per day, which is stored for a period of two years. But most of the time, queries are limited to log data created in the last seven days.
In a storage-compute linked architecture (assuming each server has a 20TB storage capacity, 3 data replicas and a 50% compression ratio), to store 700TB of data, a total of (700 TB x 3 x 50%) / 20 TB ~ 52 servers will be required. But only log data created in the last seven days is analyzed by 80% of analytics workloads, which means (7 TB x 3 x 50%) / 20 TB ~ 0.52 servers will be enough to handle most data queries. The storage of cold data, which is rarely requested, wastes more than 95% of the server's expenses.
So what is the solution?
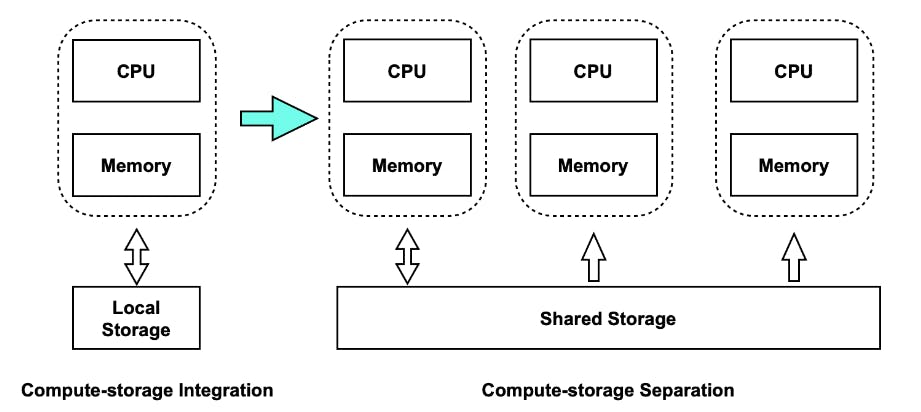
The central idea behind storage-compute separation is that data is stored in low-cost, reliable remote storage systems such as Amazon S3. This reduces storage cost, ensures better resource isolation, and high elasticity and scalability. The compute nodes can be stateless - they need not store any data with them and act upon the data stored in s3.
This enables you to scale the number of compute nodes up and down based on the query requirements. You can take this one step further by enabling intelligent caching - to cache frequently accessed data on the compute nodes itself.
If this sounds interesting to you, feel free to drop us a mail at support@ctrlb.ai and we promise to cut down your observability bills like you never imagined before!