Data is everywhere today, in apps, servers, devices, and cloud platforms. To make sense of it all, businesses need a single place to store and access this data. That’s why many use a data lake: a central system that can handle massive amounts of data in different formats.
But here’s the real challenge: getting data into the lake efficiently.
This step is called ingestion. It’s the process of pulling data from all your different sources and making it ready for use. If ingestion is slow, unreliable, or expensive, the whole data lake becomes less useful.
This blog looks at how to optimize ingestion when dealing with diverse sources, and covers key topics like connector frameworks, schema evolution, throughput, and data quality.
Why Optimized Ingestion Matters?
A data lake is like a large water reservoir. Rivers, taps, and rain all feed into it. If those sources are blocked or polluted, the reservoir doesn’t help anyone.
In the same way, ingestion ensures that:
- Data from all sources arrives in the lake.
- Data remains fresh, reliable, and consistent.
- Users can access it without waiting hours.
Optimizing ingestion means keeping this flow smooth, cost-efficient, and ready to scale.
Connector Frameworks for Heterogeneous Inputs
Organizations deal with many types of data: logs, metrics, traces, events, and SaaS records. Each comes in different shapes and speeds.
Connector frameworks help by acting as bridges between sources and the data lake:
- OpenTelemetry (OTel): Provides a standard format for collecting logs, metrics, and traces from different services. Especially useful for federating observability data across multiple platforms.
- Fluent Bit: A lightweight, fast log collector that can run at the edge (e.g., inside Kubernetes or on servers) to gather data and ship it to the lake.
- Vector: An open-source, high-performance data pipeline that collects, transforms, and routes logs and metrics from multiple sources to various destinations. It’s designed for efficiency, using minimal resources while supporting advanced processing at the edge or in centralized environments.
The right mix of connectors ensures smooth ingestion without building custom pipelines for every source.
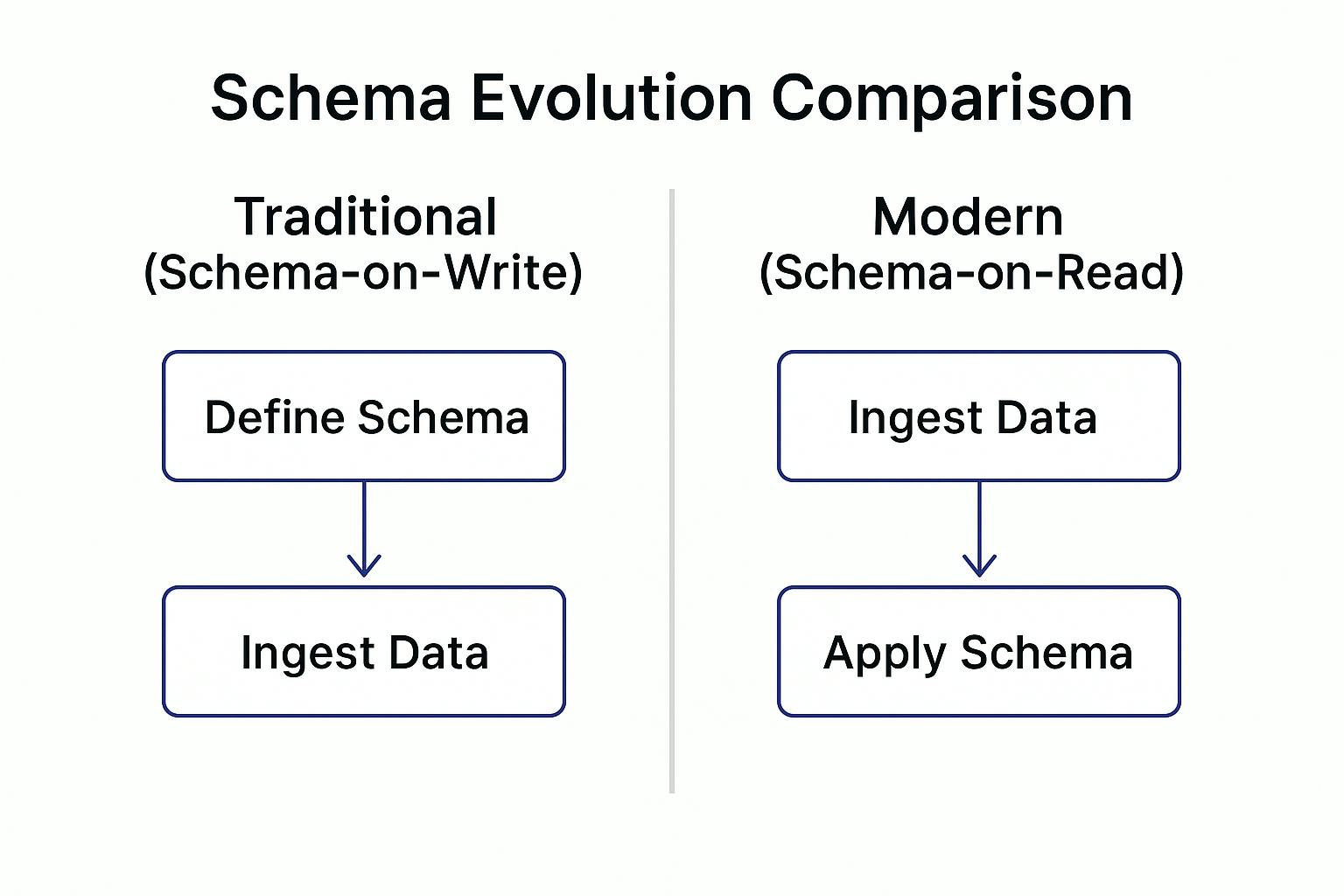
How to Handle Schema Evolution?
One of the biggest headaches with ingestion is handling schema evolution. Data formats don’t stay the same forever. A log field may get renamed, new attributes may be added, or a JSON structure may change.
If ingestion depends on a fixed schema, these changes break pipelines. That’s why modern data lakes adopt schema-on-read or schema-less ingestion.
Instead of forcing a structure at the start, raw data is stored as-is, and the schema is applied later when you query it. This makes it easy to handle new fields without rewriting ingestion logic. CtrlB, for example, supports schema-less log search, so users don’t have to worry about rigid formats.
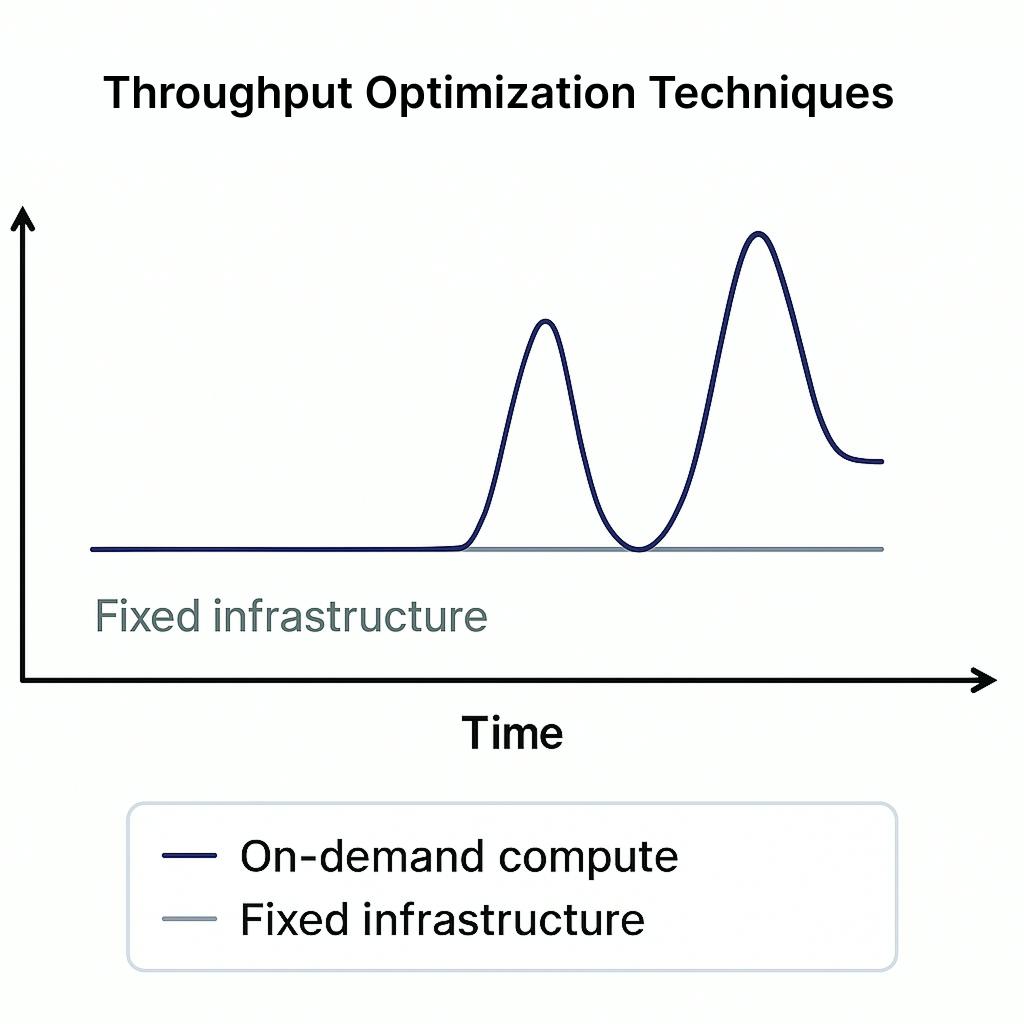
What are Some Throughput Optimization Techniques?
Data doesn’t arrive at a steady pace. Some days are quiet; other days, an outage can generate millions of log lines in minutes.
To handle this, ingestion pipelines need throughput optimization, the ability to scale up when the load is high, and scale down when it’s low. Common techniques include:
- Batching: Grouping smaller events together before writing them, reducing overhead.
- Compression: Reducing payload size to improve network speed.
- Parallelism: Processing multiple data streams simultaneously.
- On-demand compute: Instead of pre-allocating resources, compute is spun up only when needed (as CtrlB does with its Ingestor).
These techniques ensure ingestion remains cost-efficient without dropping or delaying data.
What are the Data Quality Assurance Processes?
Fast ingestion is pointless if the data itself is unusable. That’s where data quality assurance comes in.
Processes to ensure quality at ingestion include:
- Deduplication: Removing repeated data points that waste storage.
- Validation: Checking if required fields (like timestamps or IDs) exist.
- Enrichment: Adding metadata like service names or environments (prod, dev) for easier filtering later.
- Error handling: Logging ingestion failures and retrying automatically.
Without these steps, the data lake risks turning into a data swamp, full of incomplete or inconsistent records.
Putting It All Together
An optimized ingestion strategy combines all these elements:
- Connector frameworks for diverse inputs (OTel, Fluent Bit, API connectors).
- Schema flexibility to handle evolution without breaking pipelines.
- Throughput optimization to handle bursts while staying cost-efficient.
- Data quality checks to keep information reliable and usable.
When these pieces work together, the result is a unified, reliable, and future-proof data lake.
Conclusion
Optimizing ingestion is not about building bigger or more complex pipelines. It’s about designing smarter flows that handle diversity, growth, and change with ease.
By using the right connectors, supporting schema evolution, optimizing throughput, enforcing data quality, and enabling federation, organizations can ensure that their data lakes stay clean, reliable, and cost-friendly.
In the end, a data lake is only as good as what flows into it. With the right ingestion strategy, you can turn raw, scattered inputs into a unified foundation for insights, troubleshooting, and innovation.
Elevate Your Workflow
Take control of your observability
Join thousands of developers using CtrlB to monitor their systems with complete confidence and extreme precision.
Seamless Integration
Connect your entire stack in minutes with zero friction.
Real-time Analytics
Sub-second latency on all queries. No waiting.
Enterprise Grade
SOC2 Type II compliant, secure, and highly available.