Return to Blogs
PUBLISHED:Nov 16, 2025
Optimizing Kubernetes Observability with CtrlB’s Schema-Agnostic Ingestion
Kubernetes observability generates chaos. Every pod, container, and service emits logs, traces, and metrics, each in different formats. Connecting those fragments into a clear picture often feels like trying to trace a single drop of water in a storm.
Most observability stacks solve this by enforcing schemas, normalizing formats, and pre-indexing data before it’s even useful. That’s powerful but painfully rigid. In dynamic Kubernetes environments, schemas change faster than your dashboards can catch up.
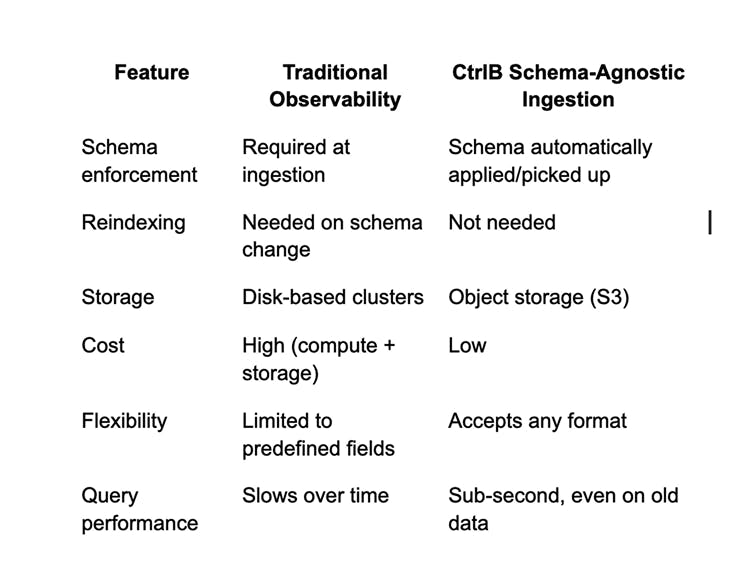
CtrlB’s schema-agnostic ingestion takes a fundamentally different route. It brings flexibility, scalability, and simplicity to Kubernetes observability, without forcing structure upfront.
Traditional observability pipelines (built on tools like Elasticsearch or Loki) require telemetry data to fit into a fixed schema before it’s stored. Every log line must be parsed, mapped, and indexed at ingestion.
That model has three big drawbacks:
In Kubernetes, where container lifespans are measured in seconds, schema rigidity becomes a constant tax on speed and clarity.
Modern solutions have evolved. Elasticsearch offers dynamic mapping. OpenTelemetry handles multiple formats. But they still apply structure early in the pipeline, limiting flexibility.
CtrlB stores raw telemetry data directly to object storage like S3 (reliable storage at S3's eleven-nines durability)
When you query, CtrlB's Ingestor engine springs into action:
This separates storage from compute completely. Data lives cheaply on S3. Compute resources activate only during queries.
For frequently-queried data, and exploratory debugging or long-term retention, CtrlB often wins..
To make onboarding effortless, CtrlB provides pre-built configurations for Kubernetes via the ctrlb-k8s repository. You can deploy it in minutes using two simple options based on your observability needs:
Option 1: Logs Only (Fluent Bit)
For teams focusing purely on log observability:
Option 2: Logs + Traces (OpenTelemetry Collector)
For full-stack observability:
Both options forward data securely to CtrlB using your instance host, stream name, and API token.
You can get started directly from the repository:
git clone https://github.com/ctrlb-hq/ctrlb-k8s.gitcd ctrlb-k8sThen, update the placeholders in the ConfigMap with your CtrlB instance details:
<INSTANCE_HOST> = your-instance-host
<STREAM_NAME> = your-stream-name
<API_TOKEN> = your-api-tokenDeploy your preferred collector:
For Fluent Bit (Logs Only):
kubectl apply -f fluent-bit/For OpenTelemetry (Logs + Traces):
kubectl apply -f otel/That’s it. Your Kubernetes cluster starts streaming logs and traces directly into CtrlB’s schema-agnostic ingestion engine.
In dynamic environments like Kubernetes, you don’t always know what you’ll need to debug tomorrow. A schema-first pipeline can’t adapt to new formats or data sources without downtime or data loss.
CtrlB’s model gives you:
Instant flexibility — Ingest any log or trace format without changing configurations.
Query-time structure — Define fields and filters only when you need them.
Unified view — Correlate logs and traces from across services seamlessly
Multi-format environments: Mix structured and unstructured data freely
Exploratory debugging: Query patterns you didn't anticipate
Long-term retention: Years of data without reindexing costs
Rapid iteration: New services ship without schema coordination.
By separating storage from compute, CtrlB eliminates traditional trade-offs between retention and speed.
You spend less time managing pipelines and more time understanding your systems.
Query Capabilities: CtrlB supports filtering, aggregation, and correlation. Complex joins require multiple passes. It's optimized for trace and log analysis.
Data Governance: Set retention policies at the S3 level. Use bucket lifecycle rules for compliance. CtrlB queries respect these boundaries automatically.
Integration: CtrlB provides APIs for Grafana and REST endpoints, so it complements existing tools.
Kubernetes environments demand flexible observability. Fixed schemas work until they don't. When that pod you never monitored becomes critical, pre-indexed fields won't help.
CtrlB's schema-agnostic model isn't universally better. It's different. It optimizes for exploration over efficiency, flexibility over speed, simplicity over features.
For teams drowning in format varieties, fighting schema drift, or exploring unknown unknowns, this tradeoff makes sense. Your raw data remains queryable forever. New questions get answers without reindexing.
Whether you deploy Fluent Bit or OpenTelemetry, CtrlB transforms telemetry chaos into on-demand clarity. No migrations. No schema committees. Just questions and answers, when you need them.
The future of Kubernetes observability might not be faster indexes or smarter schemas. It might be no schemas at all, until the moment you need them.
Join thousands of developers using CtrlB to monitor their systems with complete confidence and extreme precision.
Connect your entire stack in minutes with zero friction.
Sub-second latency on all queries. No waiting.
SOC2 Type II compliant, secure, and highly available.